|
�˹����ܣ�AI���Ǯ�ǰ�������Ƽ��g��һ�����c�������� 2019 ��h�Z�����I���[�����������C���W����ML�����ɵ� TwinCAT 3 �Ԅӻ�ܛ���С��ڽ��^��헜yԇ֮��������ȥ��ɹ��،��C���W���aƷ�����Ј����������C���W�����ɵ��� TwinCAT 3 ����ƽ�_�У�����ԓ�I��e���ˌ��F�Ľ�
���գ����� TwinCAT �aƷ���� Fabian Bause ��ʿ������WEKA �ИIý�w��Computer & AUTOMATION���s־�IJ��L�����x�߂���B������܉��������ķ�ʽ����C���W���㷨��ģ�͡�
����I������ʩ�C���W��֮ǰ����һ����ԓ��ʲô��
Fabian Bause ��ʿ������ҪԔ����������������ɹ�����C���W�������Q ML�����������횸��г�Ч���˂��ڌ����¼��g�r���������F�ɷN�O�ˑB�ȡ�Ҫô�����ȱ�����ֱ����B�ȣ�Ҫô���dz��d�^�������@Щ�¼��g����Q�^ȥ�o����ֽ�Q���y�}���҂�����ԓƫ���κ�һ�������ǿ��^�ط��� ML ����Щ�����������á�
һ���ҵ��˝��ڵ��m�ϙC���W���đ��ã��͑�ԓ���r��������ԭ�͌�ʩ���Ŀ�F꠵����������@�����P�I��ML �Ŀ���H����һ���M���^�̣����ܱ��A�O�ķ�������������ơ�
��Ŀǰ CPU �е�̎�����Ⱥ�Խ��Խ���֧���W�j�ļ��و��У�����������Էdz���Ч�ز��Ј��С���

���� Fabian Bause
������ 2019 ��ĝh�Z�����I���[���������������� TwinCAT 3 ����ƽ�_�����ϙC���W�������Ǖr�F�ڣ��C���W������Щ�����I���еı��F���^ͻ����
Fabian Bause ��ʿ��ȥ�꣬�҂��ɹ�����˜yԇ�����dz��ɹ����Ƴ����҂��ĵ�һ��aƷ �� һ���o�p���ɵ� TwinCAT 3 �еęC���W��ģ���������档ԓ��Q���������c���܉�ֱ���� TwinCAT ���r�h���Ј����W�j��ģ�ͣ��@Ҳ��ζ���@C���đ����I���ǟo�ġ�
���Ñ����棬�ѽ��γ���һ������ ML ���|�����ƺ��^�̱O�y/�����Ľ�Q������Ⱥ��һ����ȫ�Ԅӻ��Ϳ��������ɵ��|������ϵ�y�������Ի�����늙C������D�ٺ��S�`��ȬF�еęC�����������a��؛���M��ȫ�z�y�������� 7 �� 24 С�r��������Ϣ�������е�ƣ�룬�����܉F�h�h���^����������������ڕr�g���^�̱O�y�̓����ǃɂ��B�m�IJ��E�������Ӗ���õ�ģ�́��M���^�̱O�y���C������֪ͨ������T���������T�ֿ��Լ��r�{���^�̣��Ա��֮aƷ�|���ķ����ԡ���һ�������@���н��ęC�������T�W���������@�ӵķ�ʽӖ��ģ�ͣ�ģ���܉��������M������ą����{�����������g���E�����顰�������֡��l�]���ã��o�������O�ý��h��
���˿���ϵ�y������ ML �Ļ��A�M���⣬�҂�Խ��Խ�Pע�����aƷ�ڈD��̎�����\�ӿ����I��đ��ã�Ŀ���Ǟ��Ñ��ṩӲ����ܛ�����潛�^�����ĽM�����o���������� ML ֪�R����ʹ���@Щ�M����
���r�C���W�������nj���Ҫ��̎������ͬ�r�����\�и��N��ˇ�^�̵Ĺ��S܇�g���������Ȼ������Ό� ML ���ڌ��r���Ƶđ��ã����\�ӿ��Ƒ��ã�
Fabian Bause ��ʿ�����ȣ��҂�����J�R����Ӗ������ ML ��ģ��Ҫ�Ȉ��У���������Ӗ���õ�ģ�ͻ��M����ĕr�g����Ӳ�����棬�������҂��Ĺ��I PC ���\�С����܉��� CPU �и�Ч���е�һ����Ҫԭ���dz��mʹ�� SIMD ����Uչ�����Y�ϸ߶ȃ����ľ�����������⣬Ŀǰ CPU �е�̎�����Ⱥ�Խ��Խ���֧���W�j�ļ��و��У�����������Էdz���Ч�ز��Ј��С��м��^��Ӗ���õ�ģ��Ҳ�dz���Ҫ���������ֹ���������Դ���aһ�ӡ�����һ������Ч��Դ���aҪ�Ȉ���һ��������������Դ���a��Ҫ�ĕr�g�L�ܶࡣ��횸����ض����΄Ռ�Ӗ���õ� ML ģ���M���{���̓������F�ڣ����Էdz��p�ɵ،��F�뼉�W�j�����ٶȡ������҂���һ��չ�[������ 250 ����Ԫ�M�ɵĶ��Ӹ�֪�W�j��ͨ�^�҂��߶ȃ������������棬���� Intel Core i3 CPU �ϵĈ��Еr�g�H����롣��ˣ��҂����Դ_�ţ��ڈD��̎�����\�ӑ�����ʹ�� ML �r�����������治�����κ��ϵK��
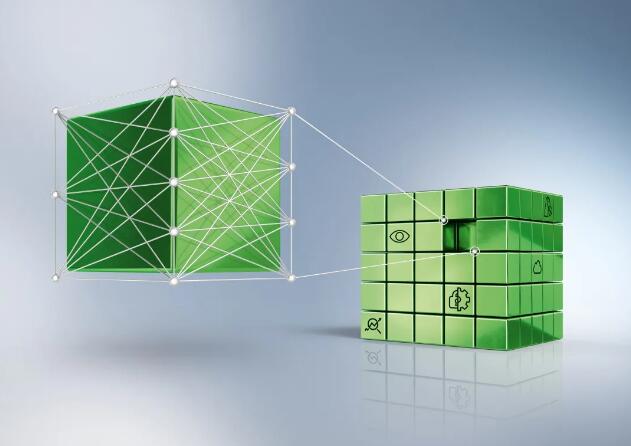
��ԓ�Εr���C���W�����ɵ������У����_�l�r߀�����\�к��ڣ�
Fabian Bause ��ʿ���������_ʼ�r�ᵽ�ģ�ML �Ŀ��һ���M���^�̣���ԓ�M�������O�������̵ărֵ������A���_ʼ�����O���ڽK�˿͑�����Ͷ��ʹ�Õr��������ÿ�����ö�����һ����ѽ�Q���������⣬���O���\�Еr�����R�e�ͷ����µ����P�������@�ӾͿ��Բ�����M ML ģ�͡������ڼ��g����֧���@һ�^�̣�������������������˽Y�����OӋ�����܉��ڲ��Д��O���\�е���r�¼��d������ģ�ͣ����o��ֹͣ TwinCAT��Ҳ�o�辎�gԴ���a���ںܶ���r�£��Ñ����O������ѽ���䲻���� ML ���ܵĿ�������������Ҫ��߮a�����������Խ��Խ��ؿ��]ʹ�� ML���@�����_��ʽ���Ʒ����l�]�P�I����֮̎���������ӿڱ��࣬��ʹ�� TwinCAT ���������b���F�еĿ��Ʒ�����Ҳ���������ϵK���҂����ѽ�ʹ�ã������^�mʹ�ã��������������� TwinCAT Machine Learning ��һ���͑����Ͽ������@һ�c����������һ�_���b�� TwinCAT 3 ܛ���ı���Ƕ��ʽ�������������ԏĵ��������������xȡ�����������M���������Ա��� TwinCAT �h���Ќ�ʩ�|������ϵ�y���ɿ��� ML �����Ԕ������������c�ͽK�c��
����x���� TwinCAT Machine Learning ��̎����Ӗ����������Ҫ�����ƌW�҆
Fabian Bause ��ʿ��ML �Ŀ��Ҫ�F������Ŀ�F��ɲ�ͬ�Č��ҽM�ɡ��F��ijɆT��ijһ�I��Č��ң����磬�C�����쎟�����ӻ����ˇ���ҡ��I�Ҵ_����Ҫͨ�^�C���W���푪�������𣬼������ѽ��O����һ��Ŀ�ˣ����Ҍ��C������Ϥ���I�ұ���c��Ҫ�Pע���������Ĕ����ƌW��һ�𣬶��x���_��Ŀ���аl�]���õĻ����C����������Щ�������ƌW�ҿ����c�I�Ҿo�ܺ������ԏ��{ij���ض�����ģʽ���О����Ҫ�ԡ�����]�Ё����I�ҵķ������߷����o�I�ң������ƌW�ҾͲ��ܳ�ְl�]���á������������͑��ľ��w��r�c�͑��`���ͨ��ijЩ�O���������ѽ��O���˔����ƌW���T����ʹ����һЩֻ��һ�����ڳ����Ǒ�Ҳ��������@��΄ա��������ܶ������̄t��Ҫ�҂��Ď�������Ȼ��Ҳ�п͑�ϵ�҂�����Ҫ�҂��ṩ��ȫ��ʽ���Ĕ����ƌW�ҷ��ա����@�N�����£��҂��ܘ��������c�҂��Č��I�������W�jȡ��ϵ��
��Ҫ��ÿ�� ML ģ�͜ʂ�Ӗ�������
Fabian Bause ��ʿ���ǵģ��@ʼ�K��һ��ǰ�ᡣ�C���W�����ǻ�������Ӗ��ģ�͵Ęӱ���������Ӗ���A�Σ�ģ�͵ą^�e��Ҫ����Ӗ�������Ƿ��И˺�������������И˺����Ϳ�����Ӗ���^�����R�e��ijһ�ض�ݔ����A��ݔ���ӱ�����Ӗ�����ھ��w�Ęӱ���������������˺���ݔ����Ϣ�͕�ȱʧ���㷨Ҳ�̓H���ڌ��҃Ȳ��ij����Pϵ�����磬�@������Ӗ����������һ����Ŀ�ľ��
��������rδ֪�r�����Ӗ��һ��ģ�́�z�y������
Fabian Bause ��ʿ���кܶ�����Ԍ��F�@��Ŀ�ˡ�һ�����^���εķ���������һ����֪e�������o������e��Ӗ��һ�����ģ�͡�ʹ�ð����o������r�Ĕ�����Ӗ��ģ�ͣ������@�M�������x�顰A ������@���^���У��㷨�R�e����A ��������������F����һ�Nδ֪�Y���������һ�Nδָ���Į�����r�r����Ҳ��һһ�R�e���������ُ��{һ�£��˹������������һ���M���A�Ρ��ڳ��m�ռ��C���������c��Y���惦��һ������ƌW�ҿ����c�I�Һ�����Ԕ��������ˇ�����Йz�y���Į�����r����Ҫ�r����ʹ��һ�����H�܉��R�e������r�������܉��Ԕ�����R�e������ģ�͡�
�P�ڵ�������BECKHOFF��
�������Ԅӻ�����˾�Ŀ���λ�ڵ������С���˾����������O�з�֧�C��������ȫ��ĺ�����飬Ŀǰ��˾�I���ѱ鼰70�������Һ͵^��
����ʼ�K�Ի���PC���Ԅӻ��¼��g���鹫˾�İlչ��������a�Ĺ��IPC�� �F������ģ�K���ӮaƷ�� TwinCAT�Ԅӻ�ܛ��������һ�������ġ�����ݵĿ���ϵ�y���ɞ���������I���ṩ�_��ʽ�Ԅӻ�ϵ�y�������Ľ�Q������30�������������˾��Ԫ����ϵ�y��Q������������صõ��ˏV���đ��á�2001��3�µ������ڱ����O���Ї��^��һ������̎��2007��5�µ��������Ϻ��������Y��˾�������Ї��^�����w���Ϻ����˺�˾�I���M����һ�����ٰlչ�r�ڣ�Ŀǰ���ڱ������V�ݡ��ɶ�����h���Ͼ���ȫ��26�����г����O�����k ��̎���S���������N���������ԃr�ȵ��®aƷ���¼��g�����M���Ї��Ј��������ڴ��Ƃ��y����ģʽ���A���ƏVPC���Ƽ��g�������ѱ�Խ��Խ����Ї��Ñ������ܡ�
������Ո�g�[��http://www.beckhoff.com.cn/cn/press/default.htm
�gӭ�Pע�����ٷ���

|
